1.1.Bắt đầu với DSA (Data Structures and Algorithms )
Cấu trúc dữ liệu và thuật toán (DSA) tạo thành nền tảng cho việc giải quyết vấn đề trong khoa học máy tính. Việc thành thạo DSA giúp bạn viết mã hiệu quả và được tối ưu hóa.
Mặc dù các khái niệm vẫn giống nhau giữa các ngôn ngữ, nhưng lựa chọn ngôn ngữ của bạn có thể định hình trải nghiệm học tập.
Hãy cùng khám phá cách bắt đầu với DSA bằng các ngôn ngữ khác nhau và những lợi thế mà mỗi ngôn ngữ mang lại.
C++
C++ thường là lựa chọn hàng đầu cho những ai tìm hiểu sâu về DSA. Sau đây là lý do tại sao nhiều người thích nó:
Kiểm soát cấp thấp: Không g
iống như các ngôn ngữ cấp cao, C++ cung cấp quyền truy cập trực tiếp vào bộ nhớ và tài nguyên hệ thống, cho phép bạn hiểu cơ chế cơ bản về cách thức hoạt động của các cấu trúc dữ liệu và thuật toán, điều này rất tuyệt vời để học DSA.
Hiệu quả: C++ cho phép chúng ta viết mã được tối ưu hóa cao, điều này rất quan trọng khi giải quyết các vấn đề quy mô lớn.
Để bắt đầu với DSA trong C++, bạn chỉ cần thiết lập môi trường C++ trên thiết bị của mình.
C
C thường được những người muốn xây dựng hiểu biết sâu sắc về cách thức hoạt động của cấu trúc dữ liệu ở cấp độ thấp ưa chuộng. Đây là lý do:
Tối thiểu trừu tượng: C có tối thiểu trừu tượng, do đó chúng ta có thể kiểm soát trực tiếp bộ nhớ và thao tác dữ liệu. Điều này giúp dễ hiểu hơn về cách các cấu trúc dữ liệu như mảng, danh sách liên kết và cây được triển khai bên trong.
Thành thạo con trỏ: Việc sử dụng con trỏ của C cung cấp kinh nghiệm thực hành với các địa chỉ bộ nhớ, điều này rất quan trọng khi làm việc với các cấu trúc dữ liệu động như danh sách liên kết, cây và đồ thị.
Để bắt đầu với DSA trong C, bạn chỉ cần thiết lập môi trường C trên thiết bị của mình.
Java
Java là một ngôn ngữ phổ biến khác để học DSA, đặc biệt là đối với người mới bắt đầu thích lập trình hướng đối tượng (OOP). Lý do chọn Java:
Tính mạnh mẽ và bảo mật: Java xử lý quản lý bộ nhớ tự động thông qua thu gom rác, giúp người mới bắt đầu dễ dàng tập trung vào việc giải quyết vấn đề hơn là quản lý tài nguyên.
Hỗ trợ cộng đồng: Với một cộng đồng lớn, có rất nhiều tài liệu, hướng dẫn và tài nguyên có sẵn để giúp bạn bắt đầu với DSA trong Java.
Để bắt đầu với DSA trong Java, bạn chỉ cần thiết lập môi trường Java trên thiết bị của mình.
Python
Python được người mới bắt đầu ưa chuộng vì tính đơn giản và dễ đọc. Sau đây là lý do tại sao Python được ưa chuộng để học DSA.
Cú pháp dễ dàng: Cú pháp của Python rõ ràng và súc tích, giúp việc học các khái niệm DSA bớt đáng sợ hơn. Bạn có thể tập trung vào việc giải thuật toán mà không phải lo lắng về tính phức tạp của ngôn ngữ.
Được gõ động: Python không yêu cầu các kiểu dữ liệu rõ ràng, giúp việc viết và kiểm tra mã dễ dàng hơn.
Để bắt đầu với DSA trong Python, bạn chỉ cần thiết lập môi trường Python trên thiết bị của mình.
JavaScript
JavaScript chủ yếu được biết đến như một ngôn ngữ để phát triển web, nhưng nó cũng được sử dụng để học DSA. Đây là lý do tại sao:
Dễ sử dụng: JavaScript có thể chạy trực tiếp trong trình duyệt, nghĩa là bạn có thể viết và kiểm tra các vấn đề DSA mà không cần thiết lập môi trường phức tạp. Điều này lý tưởng cho việc học và thử nghiệm nhanh chóng.
Tính linh hoạt: Khả năng chạy trong trình duyệt và trên máy chủ (thông qua Node.js) của JavaScript giúp dễ dàng và có thể truy cập để kiểm tra các khái niệm DSA trực tuyến.
Để bắt đầu với DSA trong JavaScript, bạn chỉ cần thiết lập môi trường JavaScript trên thiết bị của mình.
Bất kể bạn chọn ngôn ngữ nào, chìa khóa là nắm vững các khái niệm cốt lõi và luyện tập thường xuyên.
Mỗi ngôn ngữ đều cung cấp các công cụ và phương pháp tiếp cận độc đáo có thể giúp bạn hiểu sâu hơn về DSA. Hãy bắt đầu từ những điều nhỏ, xây dựng kỹ năng của bạn dần dần và áp dụng những gì bạn học được thông qua việc giải quyết vấn đề một cách nhất quán.
1.2. Thuật toán là gì?
Theo thuật ngữ lập trình máy tính, thuật toán là một tập hợp các hướng dẫn được xác định rõ ràng để giải quyết một vấn đề cụ thể. Thuật toán lấy một tập hợp các đầu vào và tạo ra đầu ra mong muốn. Ví dụ:
Một thuật toán để cộng hai số:
1.Lấy hai số đầu vào
2.Cộng các số bằng toán tử +
3.Hiển thị kết quả
Những phẩm chất của một thuật toán tốt:
1.Đầu vào và đầu ra phải được xác định chính xác.
2.Mỗi bước trong thuật toán phải rõ ràng và không mơ hồ.
3.Thuật toán phải hiệu quả nhất trong số nhiều cách khác nhau để giải quyết một vấn đề.
4.Thuật toán không nên bao gồm mã máy tính. Thay vào đó, thuật toán phải được viết theo cách có thể sử dụng trong các ngôn ngữ lập trình khác nhau.
Ví dụ về thuật toán:
Thuật toán 1:Cộng hai số do người dùng nhập vào
Bước 1: Bắt đầu Bước 2: Khai báo biến num1, num2 và sum. Bước 3: Đọc giá trị num1 và num2. Bước 4 4: Cộng num1 và num2 và gán kết quả cho tổng. sum←num1+num2 Bước 5: Hiển thị tổng Bước 6: Kết thúc
Thuật toán 2: Tìm số lớn nhất trong ba số
Step 1: Bắt đầu Step 2: Khai báo các biến a, b và c. Step 3: Đọc các biến a, b và c. Step 4: If a > b If a > c Hiển thị a là số lớn nhất. Else Hiển thị c là số lớn nhất. Else If b > c Hiển thị b là số lớn nhất. Else Hiển thị c là số lớn nhất. Step 5: Kết thúc
Thuật toán 3: Tìm nghiệm của phương trình bậc hai ax² + bx + c = 0
Step 1: Bắt đầu
Step 2: Khai báo các biến a, b, c, D, x1, x2, rp và ip;
Step 3: Tính toán Delta
D ← \(b^2\)-4ac
Step 4: If D ≥ 0
r1 ← (-b+√D)/2a
r2 ← (-b-√D)/2a
Hiển thị r1 và r2 là nghiệm phương trình.
Else
Tính phần thực và phần ảo
rp ← -b/2a
ip ← √(-D)/2a
Hiển thị rp+j(ip) và rp-j(ip) là nghiệm phương trình
Step 5: Kết thúc
Thuật toán 4: Tìm giai thừa của một số
Step 1: Bắt đầu
Step 2: Khai báo các biến n, giai thừa và i.
Step 3: Khởi tạo biến
factorial ← 1
i ← 1
Step 4: Đọc giá trị của n
Step 5: Lặp lại các bước cho đến khi i = n
5.1: factorial ← factorial*i
5.2: i ← i+1
Step 6: Hiển thị giai thừa
Step 7: Kết thúc
Thuật toán 5: Kiểm tra xem một số có phải là số nguyên tố hay không
Step 1: Bắt đầu
Step 2: Khai báo các biến n, i, flag.
Step 3: Khởi tạo biến
flag ← 1
i ← 2
Step 4: Đọc n từ người dùng.
Step 5: Lặp lại các bước cho đến khi i=(n/2)
5.1 Nếu phần dư của n÷i bằng 0
flag ← 0
Đi tới bước 6
5.2 i ← i+1
Step 6: If flag = 0
Hiển thị n không phải là số nguyên tố
else
Hiển thị n là số nguyên tố
Step 7: Kết thúc
Thuật toán 6: Tìm dãy số Fibonacci cho đến số hạng nhỏ hơn 1000
Step 1: Bắt đầu
Step 2: Khai báo các biến first_term,second_term và temp.
Step 3: Khởi tạo biến first_term ← 0 second_term ← 1
Step 4: Hiển thị first_term và second_term
Step 5: Lặp lại các bước cho đến khi second_term ≤ 1000
5.1: temp ← second_term
5.2: second_term ← second_term + first_term
5.3: first_term ← temp
5.4: Hiển thị second_term
Step 6: Kết thúc
1.3. Cấu trúc dữ liệu và phân loại
1.3.1.Cấu trúc dữ liệu là gì?
Cấu trúc dữ liệu là một bộ lưu trữ được sử dụng để lưu trữ và sắp xếp dữ liệu. Đây là một cách sắp xếp dữ liệu trên máy tính để có thể truy cập và cập nhật dữ liệu một cách hiệu quả.
Tùy thuộc vào yêu cầu và dự án của bạn, điều quan trọng là phải chọn đúng cấu trúc dữ liệu cho dự án của bạn. Ví dụ, nếu bạn muốn lưu trữ dữ liệu theo trình tự trong bộ nhớ, thì bạn có thể sử dụng cấu trúc dữ liệu Mảng
Lưu ý: Cấu trúc dữ liệu và kiểu dữ liệu hơi khác nhau. Cấu trúc dữ liệu là tập hợp các kiểu dữ liệu được sắp xếp theo thứ tự cụ thể.
1.3.2. Các loại cấu trúc dữ liệu
Về cơ bản, cấu trúc dữ liệu được chia thành hai loại:
-Cấu trúc dữ liệu tuyến tính
-Cấu trúc dữ liệu phi tuyến tính
Chúng ta hãy tìm hiểu chi tiết về từng loại.
a.Cấu trúc dữ liệu tuyến tính
Trong cấu trúc dữ liệu tuyến tính, các phần tử được sắp xếp theo trình tự lần lượt. Vì các phần tử được sắp xếp theo thứ tự cụ thể nên chúng dễ triển khai.
Tuy nhiên, khi độ phức tạp của chương trình tăng lên, cấu trúc dữ liệu tuyến tính có thể không phải là lựa chọn tốt nhất do tính phức tạp của hoạt động.
Cấu trúc dữ liệu tuyến tính phổ biến là:
1. Cấu trúc dữ liệu mảng
Trong một mảng, các phần tử trong bộ nhớ được sắp xếp trong bộ nhớ liên tục. Tất cả các phần tử của một mảng đều có cùng kiểu. Và, kiểu phần tử có thể được lưu trữ dưới dạng mảng được xác định bởi ngôn ngữ lập trình.
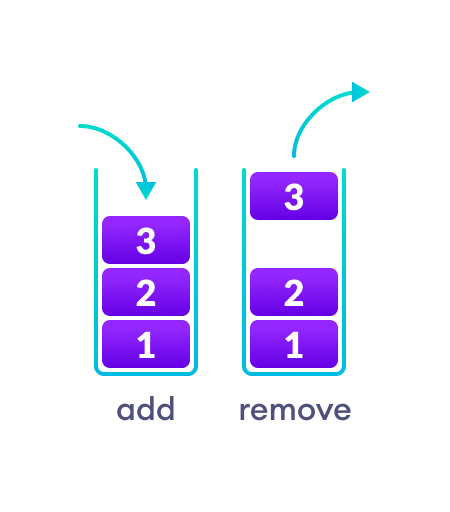
2. Cấu trúc dữ liệu ngăn xếp
Trong cấu trúc dữ liệu ngăn xếp, các phần tử được lưu trữ theo nguyên tắc LIFO. Nghĩa là, phần tử cuối cùng được lưu trữ trong ngăn xếp sẽ được xóa trước.
Nó hoạt động giống như một chồng đĩa, trong đó đĩa cuối cùng được giữ trên chồng sẽ được xóa trước.
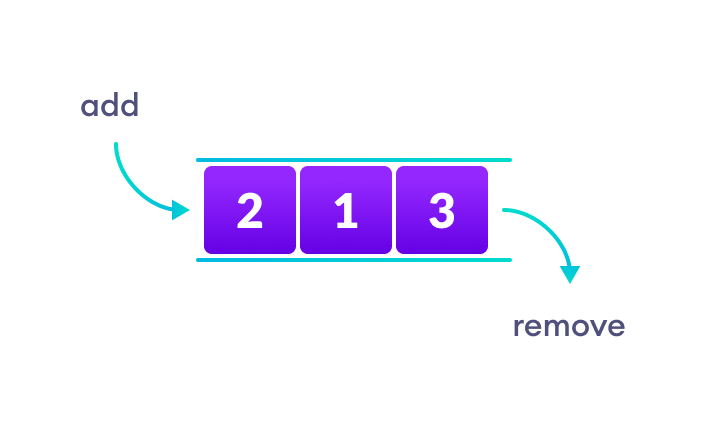
3. Cấu trúc dữ liệu hàng đợi
Không giống như ngăn xếp, cấu trúc dữ liệu hàng đợi hoạt động theo nguyên tắc FIFO, trong đó phần tử đầu tiên được lưu trữ trong hàng đợi sẽ được xóa trước.
Nó hoạt động giống như một hàng người trong quầy bán vé, trong đó người đầu tiên trong hàng đợi sẽ lấy được vé trước.
4. Cấu trúc dữ liệu danh sách liên kết
Trong cấu trúc dữ liệu danh sách liên kết, các phần tử dữ liệu được kết nối thông qua một loạt các nút. Và mỗi nút chứa các mục dữ liệu và địa chỉ đến nút tiếp theo.
b.Cấu trúc dữ liệu phi tuyến tính
Không giống như cấu trúc dữ liệu tuyến tính, các phần tử trong cấu trúc dữ liệu phi tuyến tính không theo bất kỳ trình tự nào. Thay vào đó, chúng được sắp xếp theo cách phân cấp, trong đó một phần tử sẽ được kết nối với một hoặc nhiều phần tử.
Cấu trúc dữ liệu phi tuyến tính được chia thành cấu trúc dữ liệu dạng đồ thị và dạng cây.
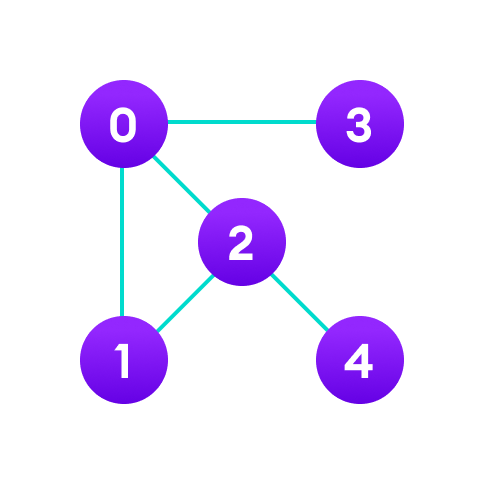
1. Cấu trúc dữ liệu đồ thị
Trong cấu trúc dữ liệu đồ thị, mỗi nút được gọi là đỉnh và mỗi đỉnh được kết nối với các đỉnh khác thông qua các cạnh.